こんにちは。Holmesでエンジニアをしている山本です。
社内でATDDの話題が出たことがありました。受け入れテストと言えばCucumber 、というイメージがあったのですが、他にないか調べたところ、Gauge という、Markdown を仕様としてテスト実行できるツールがあったので、試してみました。
実行環境
Gaugeの概要
テスト仕様(CucumberにおけるFeatureファイル)をMarkdown で記述し、それと紐づけたテスト(CucumberにおけるStepファイル)を実行できる、テストフレームワーク です。
概要は、Gaugeによるe2eテスト - Speaker Deck に詳しいです。
※スライド内でGaugeのURLが https://getgauge.io/ となっていますが、現在では https://gauge.org/ です。また、ライセンスがGPL3.0との記載がありますが、2020/4月末に変更され 、v1.1.5の時点ではApache License 2.0になっています。
テストとして実行可能な言語は、v1.1.5の時点でC# , Java , JavaScript , Python , Ruby の5種類が選択です。また、Visual Studio Code でのプロジェクト作成時には、TypeScriptも選択できました。
なぜGaugeを試そうと思ったのか
現状、ユニットテスト とインテグレーションテストの区別なく、Spock を用いたテストを記述しています。
ユニットテスト では、依存クラスをモック化したテストを書けるのですが、インテグレーションテストを書こうとすると、データの事前準備など、テスト以外の記述がどうしても増えてしまいます。
前処理/後処理の共通化 などを行っていますが、単一のテストクラス内では共通化 できているが、複数のテストクラスを見比べると同じような処理が書かれていたり、あるメソッドでは共通処理を使っているが別のメソッドでは個別に初期化処理を行ったりと、標準化が難しい状態です。
こうした状態の改善のため、テストの仕様と実装を切り分け、テスト仕様を自然言語 で記述できれば、データ作成などの共通化 が、仕様と実装が混在している現在よりも容易に行えるのではないかと思います。
また、弊社ではSelenium を利用したリグレッション テストをOPS チームの方々が記述してくれています。それらについても、テストの仕様と実装を切り分けていれば、共通のテスト仕様を元に、実装を切り替えることができるのではないかと考えました。
これらはCucumberでも達成可能だと思いますが、Cucumberのテスト仕様に用いるGherkin構文 を覚えるよりも、ルールがあるとはいえMarkdown を利用できたほうが学習コストが低くなると思い、今回はGaugeを試してみようと思います。*1
環境構築
公式としては、Visual Studio Code をEditorとして、開発元が同じブラウザ操作自動化ツールのTaiko を用いたJavaScript によるテスト実装を推奨しているようです。
弊社では標準開発環境としてIntellij IDEAを使用しているため、今回はIntellij IDEAをIDE として、Java +Selenium によるE2Eテスト実装を試してみます。
こちらの記事 を参考としました。
Gaugeのインストール
公式のインストールガイド にて、OS、プログラミング言語 、IDE /Editorを選択すると、それ以降のページの記述が変わる仕組みです。
v1.1.5時点では開発環境としてVisual Studio Code しか選択できないようです。
ひとまず、Windows 用インストーラ ーをダウンロードして、Gaugeをインストールします。
インストールガイドでのIDE には表示されていませんが、Intellij IDEAにもGaugeプラグイン があるため、インストールします。*2
Intellij IDEAからGaugeプロジェクトの作成Gaugeプラグイン をインストールすると、Intellij IDEAの File > New > Project にて、Gaugeプロジェクトを作成可能となります。
SQL Support にチェックせず NextProject name, Project location, Project SDK をそれぞれ設定し、Finish
作成されたプロジェクトは、Maven プロジェクトでもGradleプロジェクトでもない、素のJava プロジェクトになっていました。また、依存性などにSelenium が使われておらず、単純なユニットテスト の実行のみとなっていました。
いくつか外部ライブラリが読み込まれていますが、どこで設定しているか確認すると、プロジェクトルートに プロジェクト名.iml が作成され、 jarDirectory として file://$USER_HOME$/AppData/Roaming/gauge/plugins/java/0.7.13/libs を読み込んでいました。
このファイルをVCS に追加して使い回す場合、Windows でしか動かせなさそうなこと、またSelenium がデフォルトの依存性に含まれていなかったことから、Intellij IDEAでのプロジェクト作成を断念し、Visual Studio Code からMaven プロジェクトを作成することにしました。
Visual Studio Code にGaugeプラグイン をインストールします。
公式のプロジェクト作成手順 を元に、Java を実装言語とした、Gaugeプロジェクトを作成します。
Java でもプロジェクトの種類が複数ありますが、今回は java_maven_selenium プロジェクトを選択、作成しました。
作成されたプロジェクトの pom.xml を見ると、Selenium が依存性に含まれていました。また、先ほどはディレクト リを参照していたライブラリ関連も、 com.thoughtworks.gauge:gauge-java:0.7.13 として依存性が追加されていました。
ただし、デフォルトでは文字コード の指定がされておらず、Windows 環境ではファイルをMS932で読み込もうとするため、project 直下に、 以下の記述を追加しておきます。
<properties>
<project build sourceEncoding> UTF-8</project build sourceEncoding>
</properties>
Gaugeの実行確認
Java でのGaugeの実行にはJDK11以上が必要ということで、環境変数 PATH にJDK11のbinを通し、 mvn test を実行するか、Visual Studio Code 上で specs/example.spec を開いて Run Spec をクリックし、実行できることを確認します。
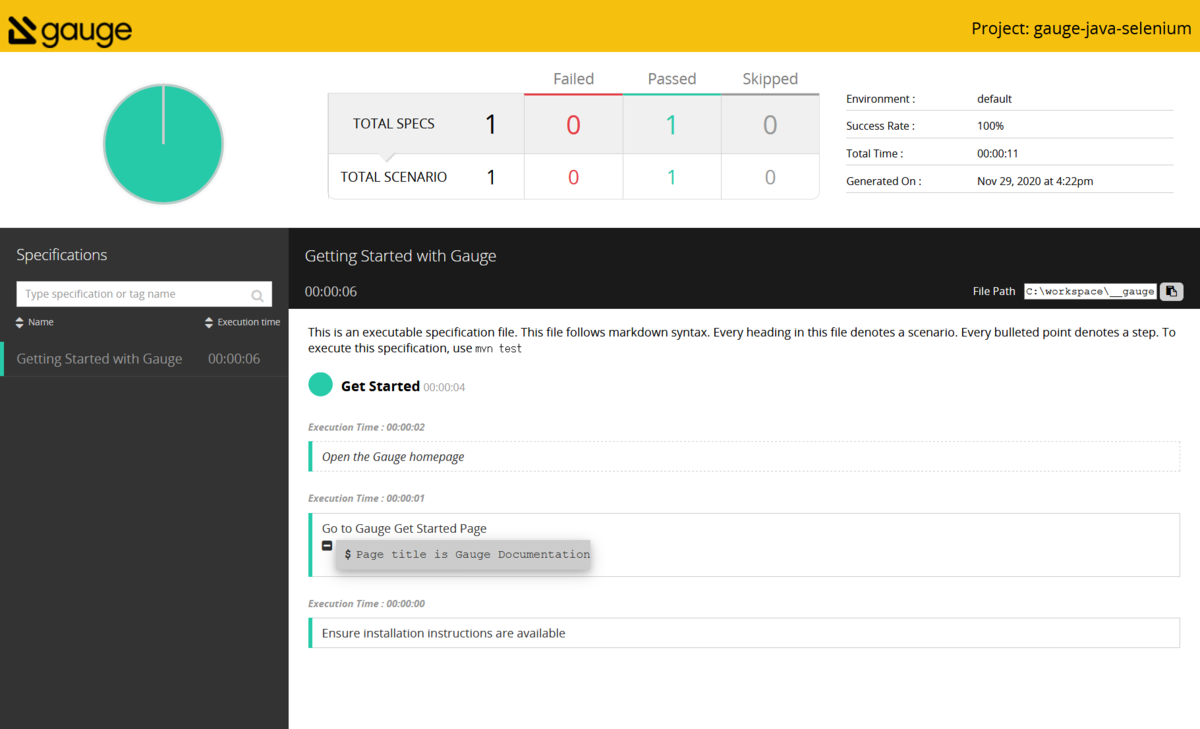
テストがパスし、 reports/html-report/index.html が作成されれば成功です。ファイルを開くと、以下のレポートが表示されます。
初期状態でのレポート
Intellij IDEAでのプロジェクトインポートVisual Studio Code を使って、プロジェクト作成はできました。改めてIntellij IDEAでプロジェクトを開いて、Maven プロジェクトとしてインポートします。
インポートした後、 specs/example.spec を開くと、Gaugeプラグイン をインストールしていれば、Markdown の見出し部分に、通常のテストクラスと同様の実行ボタンが表示されます。
これをクリックし、テストが実行されることを確認しました。
実装
いよいよ実装です。テスト仕様をMarkdown で、テスト実装をJava で記述し、それぞれをマッピング していきます。
記述方法の詳細は、公式ドキュメント を参照してください。
今回は、先ほどの記事 やこちらの記事 を元に、Google またはBingを開き、「Holmes開発者ブログ」で検索し、検索結果ページのタイトルを確認してみようと思います。
テスト仕様の記述
specs/ ディレクト リ配下に拡張子 .spec として、Markdown でテスト仕様を記述していきます。
他にも拡張子 .cpt として、再利用可能な仕様を「コンセプト」として記述できるようですが、今回は使用しません。
今回は、以下のようなMarkdown を記述し、 specs/search.spec として保存しました。*3
# 検索エンジンの検索結果ページのタイトルを確認する
Tags: search
|url |inputSelector |title |
|-----------------------|--------------------|--------------------------------|
|https://www.google.com/|#tsf input[name="q"]|Holmes開発者ブログ - Google 検索|
|https://www.bing.com/ |#sb_ form_ q |Holmes開発者ブログ - Bing |
## 検索エンジンを開き、「Holmes開発者ブログ」で検索し、検索結果ページのタイトルを確認する
Tags: successful
* 検索エンジンのURL < url> を開く
* 検索文字列入力欄 < inputSelector> を取得する
* "Holmes開発者ブログ" で検索する
* 検索結果ページのタイトルが < title > であることを確認する
h1 タグが見出し、 h2 タグがシナリオとなります。
見出しとシナリオの間にテーブルを記述すると、データテーブルとして、パラメーター化テストが可能です。
シナリオ配下に順序なしリストを記述すると、それぞれがテストのステップとなります。注意点として、Markdown では順序なしリストの記述に *|+|- のいずれかを使用できますが、Gaugeでは * のみ有効のようです。
ステップに " で囲んだ部分は静的パラメータ、 < と > 囲んだ部分は動的パラメータとなります。動的パラメータには、データテーブルのヘッダ名を記述することで、その値が設定されます。このとき、値の末尾の空白は、自動でトリミングされます。
見出しと最初のシナリオの間にステップを記述すると、コンテキストステップとして、各シナリオの実行前の共通処理を記述できるようですが、今回は使用しません。
Intellij IDEA上でも、Gaugeプラグイン をインストールしておくと、実装のないステップはエラーとなっていました。
テスト実装の記述
テスト仕様のステップに対応するテスト実装を記述します。
Java の場合、テストメソッドに com.thoughtworks.gauge.Step アノテーション を付与し、ステップとマッピング します。
WebDriver インスタンス は、 driver.Driver.webDriver に設定されているので、明示的に生成する必要はありません。デフォルトでは、 ChromeDriver が設定されます。
以下のテストクラスを、 src/test/java/search/SearchSteps.java に記述しました。アサーション ライブラリとしては、AssertJ がデフォルトで依存性に含まれているため、それを使用しています。
package search;
import com.thoughtworks.gauge.Gauge;
import com.thoughtworks.gauge.Step;
import com.thoughtworks.gauge.datastore.ScenarioDataStore;
import driver.Driver;
import org.openqa.selenium.By;
import org.openqa.selenium.Keys;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.WebElement;
import static org.assertj.core.api.Assertions.assertThat;
public class SearchSteps {
private final WebDriver driver = Driver.webDriver;
@Step( "検索エンジンのURL <url> を開く" )
public void openSearchEngine(String url) {
driver.get(url);
}
@Step( "検索文字列入力欄 <inputSelector> を取得する" )
public void getSearchTextInput(String inputSelector) {
WebElement searchTextInput = driver
.findElement(By.cssSelector(inputSelector));
ScenarioDataStore.put("searchTextInput" , searchTextInput);
}
@Step( "<searchText> で検索する" )
public void searchTextInput(String searchText) {
WebElement searchTextInput = (WebElement) ScenarioDataStore
.get("searchTextInput" );
searchTextInput.sendKeys(searchText);
searchTextInput.sendKeys(Keys.chord(Keys.ENTER));
}
@Step( "検索結果ページのタイトルが <title> であることを確認する" )
public void checkSearchResultPageTitle(String title) {
String pageTitle = driver.getTitle();
Gauge.writeMessage("検索結果ページのタイトル: %s" , pageTitle);
assertThat(pageTitle).isEqualTo(title);
}
}
JUnit のテストクラスのようですが、依存性にJUnit は含まれていないため、テストクラスへの @Test などのアノテーション は不要です。
各テストメソッド間での値の受け渡しには、それぞれライフサイクルの異なる DataStore が利用可能です。今回はシナリオ内での値の受け渡しに、 ScenarioDataStore を利用しています。
また、 Gauge.writeMessage メソッドで、レポートにメッセージを追加することができます。
@Step で記述したテキスト内のパラメータ数と、メソッドの引数の数に不一致があるとエラーとなるなど、テスト実装でもGaugeプラグイン をインストールしておけば、Intellij IDEA上でチェックが行われるようになっていました。
実行と結果の確認
mvn test を実行すると、 example.spec に続いて、 search.spec の実行が行われます。実行順は、ファイル名の昇順のようです。
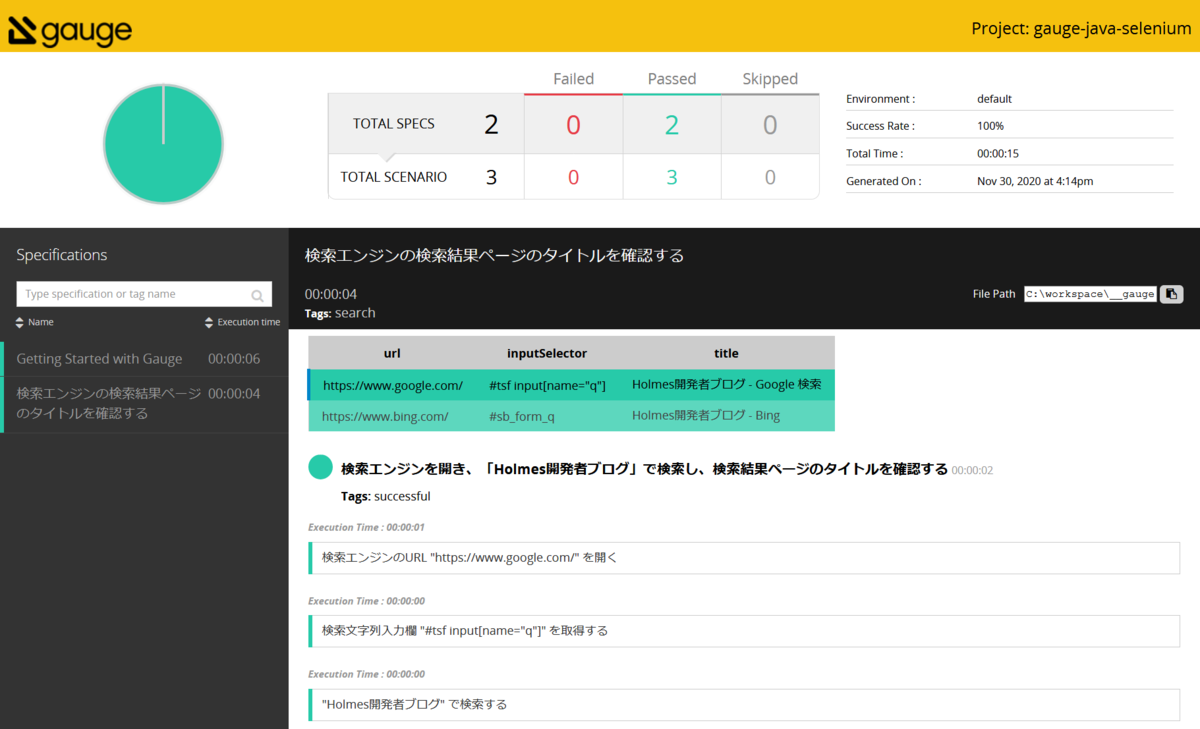
reports/html-report/index.html を開くと、追加したテストの結果を含んだレポートが出力されています。
テスト追加後のレポート
左フレームのスペック名を選択して、表示を切り替えることができます。タグ付けしておくことで、検索も可能です。
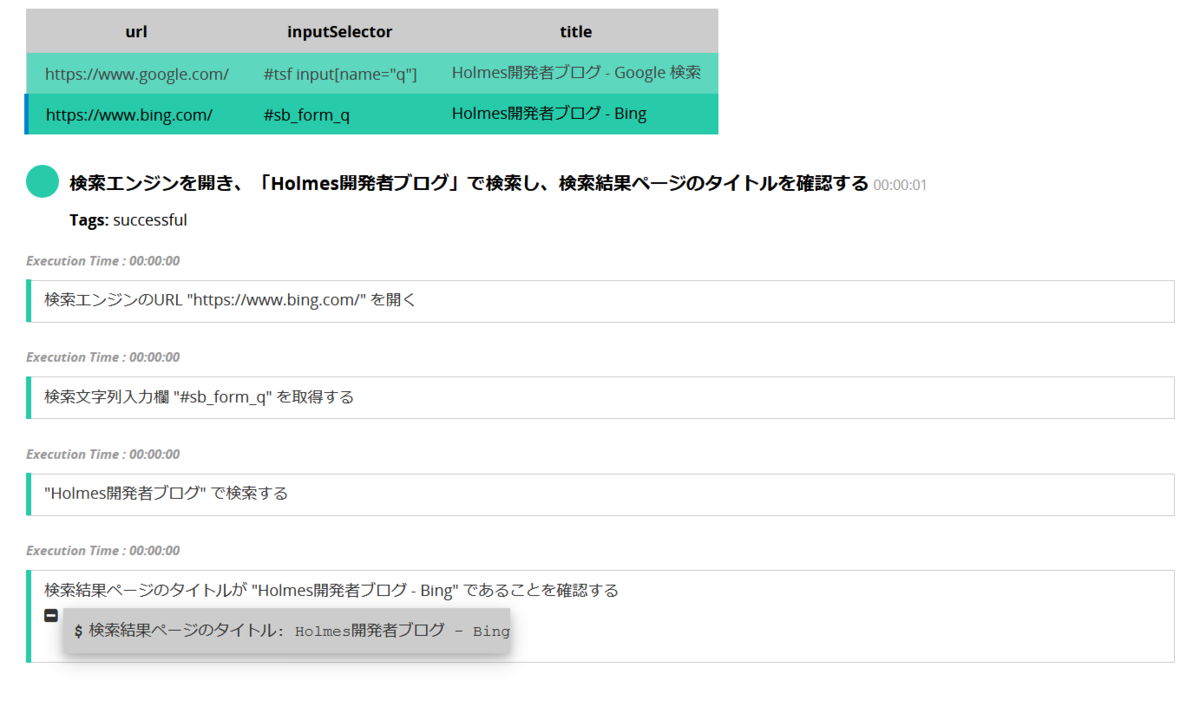
データテーブルを使用した場合、テーブル内容が表示され、行をクリックすることでテスト結果の表示を切り替えることができます。
Bingの行選択時
Gauge.writeMessage で出力したメッセージも確認できました。
感想
テスト仕様の記述については、単純なMarkdown のため、非常に書きやすいです。Cucumberなどをしっかりと使ったことがなく、概要だけ調べての感想になりますが、Gherkinに比べると、導入に際してのハードルは低いと思います。
いっぽう、テスト仕様の表現力という意味だと、「given/when/then」、日本語では「前提/もし/ならば」といった記述をキーワードとして行えるGherkinのほうが高いと感じました。今回の記述量程度であれば、IDE /Editorのコード補完やコンパイル エラーの有無で管理できますが、GaugeでもGherkinと同様、テストの準備では「前提」を使用したり、前処理の実装はこのファイルに記述するなどの取り決めをしておくと、テストが増えてもメンテナンスがしやすくなると思います。
実装については、公式でIDE /EditorとしてVisual Studio Code しか選択できなかったため、やや不安がありましたが、Visual Studio Code でプロジェクトさえ作ってしまえば、Intellij IDEA + Gaugeプラグイン で問題なく行えました。今回はサンプルコードのため、テスト実装内でSelenium を使っていろいろと操作を行いましたが、保守性を高めるためには、Page Object Patternに基づいたクラスを別途記述し、Gaugeはそのオーケストレーション に専念したほうがいいと思います。
また、テスト結果のレポートについては、エラーが起こった場合は自動でスクリーンショット が添付されるなど、非常に見やすいと思います。*4
※Cucumberでのレポート出力については、ちょっと調べた限り公式 ではCucumber Reports Service が推奨されていたり、Allure Framework などサードパーティ 製ライブラリがあるものの、デフォルトでどんなレポートが出力されるかが分からず、比較はできませんでした。
Gauge自体はSelenium に依存するものではないため、ブラウザ操作を伴うテスト以外でも、受け入れテストやリグレッション テストなど、繰り返し行うテストの自動化およびレポート出力に使えそうだと感じました。
最後に
Holmesではエンジニア・デザイナーを募集しております。ご興味がある方はこちらからご連絡ください。
lab.holmescloud.com
lab.holmescloud.com